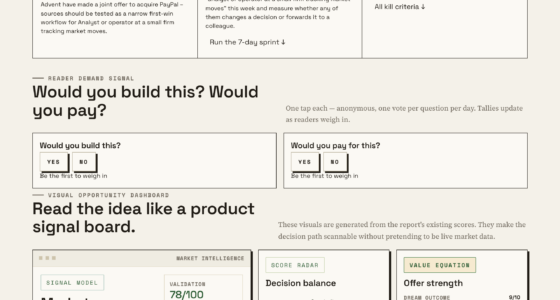
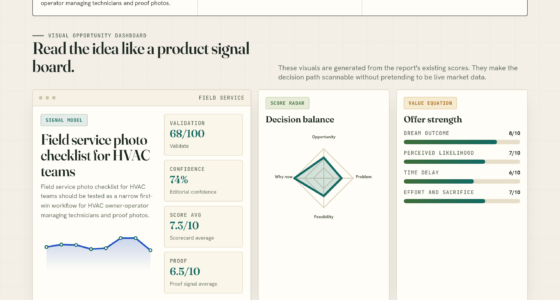
TL;DR
Google’s May 2026 whitepaper The New SDLC With Vibe Coding argues that AI-assisted development is moving from code-writing toward intent-setting, with verification becoming the main test of maturity. The paper reports broad use of AI coding agents, but its sharper claim is that model choice is only a small part of agent behavior compared with the engineering harness around it.
Google’s May 2026 whitepaper, The New SDLC With Vibe Coding, argues that software teams using AI coding agents should focus less on model choice and more on verification, tooling and workflow design, a shift that could change how engineering leaders budget for AI-assisted development.
The paper, written by Addy Osmani, Shubham Saboo and Sokratis Kartakis, says software engineering is moving from writing code directly to expressing intent and asking machines to produce working software. According to the paper, 85% of professional developers regularly use AI coding agents, 51% use them daily and about 41% of all new code is AI-generated.
The authors frame AI-assisted software work as a spectrum. At one end is casual “vibe coding,” where developers accept outputs with limited review. At the other is “agentic engineering,” where AI-generated work is constrained by formal specifications, automated tests, evals, CI/CD gates and human architectural oversight.
The paper’s most consequential claim is that an agent’s behavior is shaped less by the model than by the surrounding harness: prompts, tools, context policies, hooks, sandboxes, sub-agents and observability. The source material says the paper gives a rough split of about 10% model and 90% harness, citing examples including a Terminal Bench 2.0 improvement from outside the Top 30 to the Top 5 by changing only the harness, and a LangChain experiment that raised an agent score by 13.7 points through changes to prompts, tools and middleware.
The model is only 10%
A Google whitepaper argues software’s biggest shift is from writing code to expressing intent. Its sharpest claim: the model you obsess over is the smallest part of the system — the scaffolding around it does the real work.
The clearest map yet of how serious AI development works — and mostly tool-agnostic. But it’s a Google funnel: the concepts are neutral, the on-ramps point to Gemini, Jules & the ADK. If the harness is 90% and it’s yours, your moat and your costs both live there — so own your scaffolding, route across models, and remember: AI amplifies whatever engineering culture it lands in.
Verification Becomes the Bottleneck
The paper matters because it shifts the AI coding debate away from asking which model is best and toward asking whether teams can reliably check what agents produce. If the paper’s framing holds, engineering maturity will depend on specs, tests, evals, routing, observability and review systems rather than prompt skill alone.
That has budget implications. The source analysis describes a trade-off between low upfront cost and high later cost in casual AI use, including repeated fix-it loops, maintenance debt and security cleanup. By contrast, agentic engineering requires more setup work but may lower cost per shipped feature when teams reuse strong harnesses across projects.
![Claude AI for Beginners Bible: [5 in 1] The Ultimate Guide to Automate Your Work, Save Hours Every Week, and Use AI for Real-World Results](https://m.media-amazon.com/images/I/415+fSJacsL._SL500_.jpg)
Claude AI for Beginners Bible: [5 in 1] The Ultimate Guide to Automate Your Work, Save Hours Every Week, and Use AI for Real-World Results
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
From Vibes to Agentic Engineering
The phrase “vibe coding” was popularized by Andrej Karpathy in February 2025 to describe a loose style of AI-assisted programming in which developers lean on generated code and iterate by feeding errors back into the model. The Google paper, as summarized by Thorsten Meyer AI, treats that approach as one end of a broader software development spectrum rather than as a label for all AI coding.
The source analysis also flags a commercial angle. It says the whitepaper’s concepts are mostly tool-neutral, but its practical on-ramps point toward Google products including Gemini, Jules and the Agent Development Kit. That means the paper can be read both as a useful engineering framework and as part of Google’s push to shape enterprise AI development workflows.
“generation is solved; verification, judgment, and direction are the new craft”
— Osmani, Saboo and Kartakis, in the Google whitepaper

Portable Mini Inductor Tester, Type-C Powered High Precision Mainboard Coil Testing Tool, Fast Inductance Fault Detection Diagnosis Repair Tool for Mobile Phone Electronic Components-2 Pcs
Instant Inductor– In-Circuit Friendly:Simply bring the sensing tip close to the target inductor directly on the board –…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Benchmarks Still Need Translation
Several details remain unsettled. The source material does not provide the full methodology behind the reported adoption figures, the Terminal Bench 2.0 example or the LangChain score increase, so readers should treat those as reported findings from the paper rather than independently verified measurements here.
It is also not yet clear how consistently the 10% model and 90% harness split applies across teams, domains and risk levels. Highly regulated systems, security-sensitive code and legacy codebases may face different costs than the paper’s broad framework suggests.

Automating DevOps with GitLab CI/CD Pipelines: Build efficient CI/CD pipelines to verify, secure, and deploy your code using real-life examples
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Teams Test Their Harnesses
The next test is whether engineering organizations act on the paper’s recommendations by auditing AI coding workflows, adding evals for agent behavior and measuring whether stronger harnesses reduce rework. Vendors are likely to keep packaging these controls into agent platforms, while larger teams may build their own scaffolding to avoid being locked into one model provider.
For now, the practical takeaway is narrow but clear: teams using AI to ship production software need to measure not only what the agent writes, but how the surrounding system steers, checks and records that work.

ANCEL BD300 Bluetooth OBD2 Scanner, Full System Code Reader and Diagnostic Tool for BMW with Battery Registration Service Reset EPB CBS ETC ABS Airbag & Powerful OBD2 Functions
【Bluetooth OBD2 Scanner Designed for BMW】The ANCEL BD300 is a cost-effective obd2 scanner diagnostic tool designed for BMW/MINI/Rolls-Royce…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What is the actual news development?
Google published a May 2026 whitepaper arguing that AI-assisted software development is moving toward intent-driven, agentic workflows where verification and engineering controls matter more than model choice alone.
Is the paper saying models no longer matter?
No. The paper still treats the model as part of the system. Its claim is that the surrounding harness often has a larger effect on reliability, cost and output quality than teams assume.
What does “vibe coding” mean here?
In this framing, vibe coding means casual AI-assisted coding with loose prompts, limited review and informal checks. The paper contrasts that with agentic engineering, where AI output is tested, evaluated and governed through production-grade workflows.
What is an AI coding harness?
The harness is the set of controls around the model: prompts, tool access, project context, sandboxes, hooks, sub-agents, observability, test suites and evals. The paper argues that this layer shapes most real-world agent behavior.
What is still unproven?
The broad direction is clear from the paper’s argument, but the generality of its 10% model and 90% harness framing remains uncertain. Teams will need their own measurements to know whether the same cost and reliability patterns apply to their codebases.
Source: Thorsten Meyer AI